Inference
37 curated articles on Inference for AI engineers
37 articles

Pragmatic Engineer· 6 min read· 3 days ago
The Pulse: a new trend, smart model routing

AWS ML Blog· 13 min read· 3 days ago
How Amazon Bedrock catches AI-generated phishing
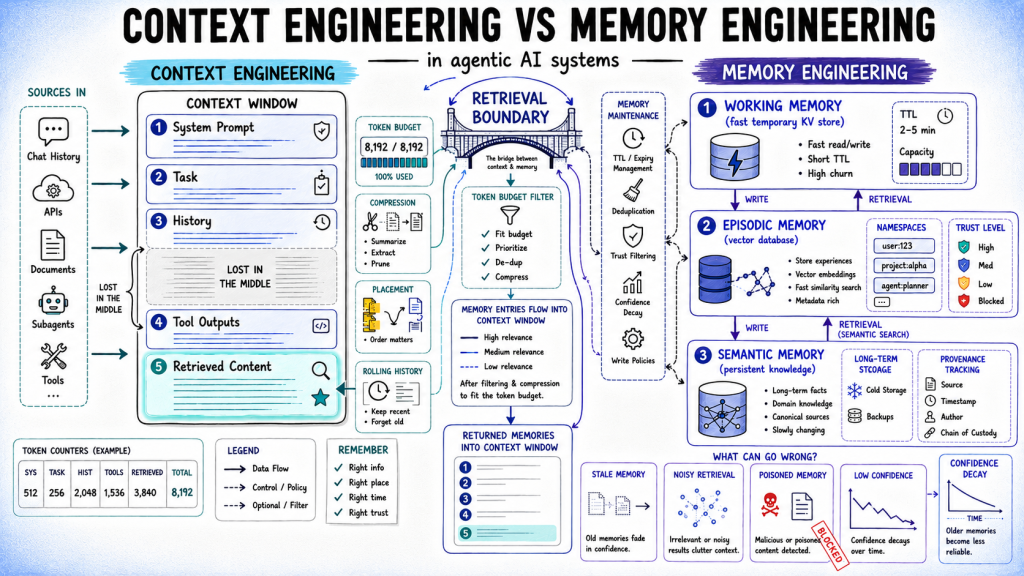
Machine Learning Mastery· 3 days ago
Context vs. Memory Engineering in Agentic AI Systems

NVIDIA Blog· 4 min read· 3 days ago
NVIDIA Unlocks AI Compute at Scale, Inviting Partners to Power the AI Infrastructure Buildout
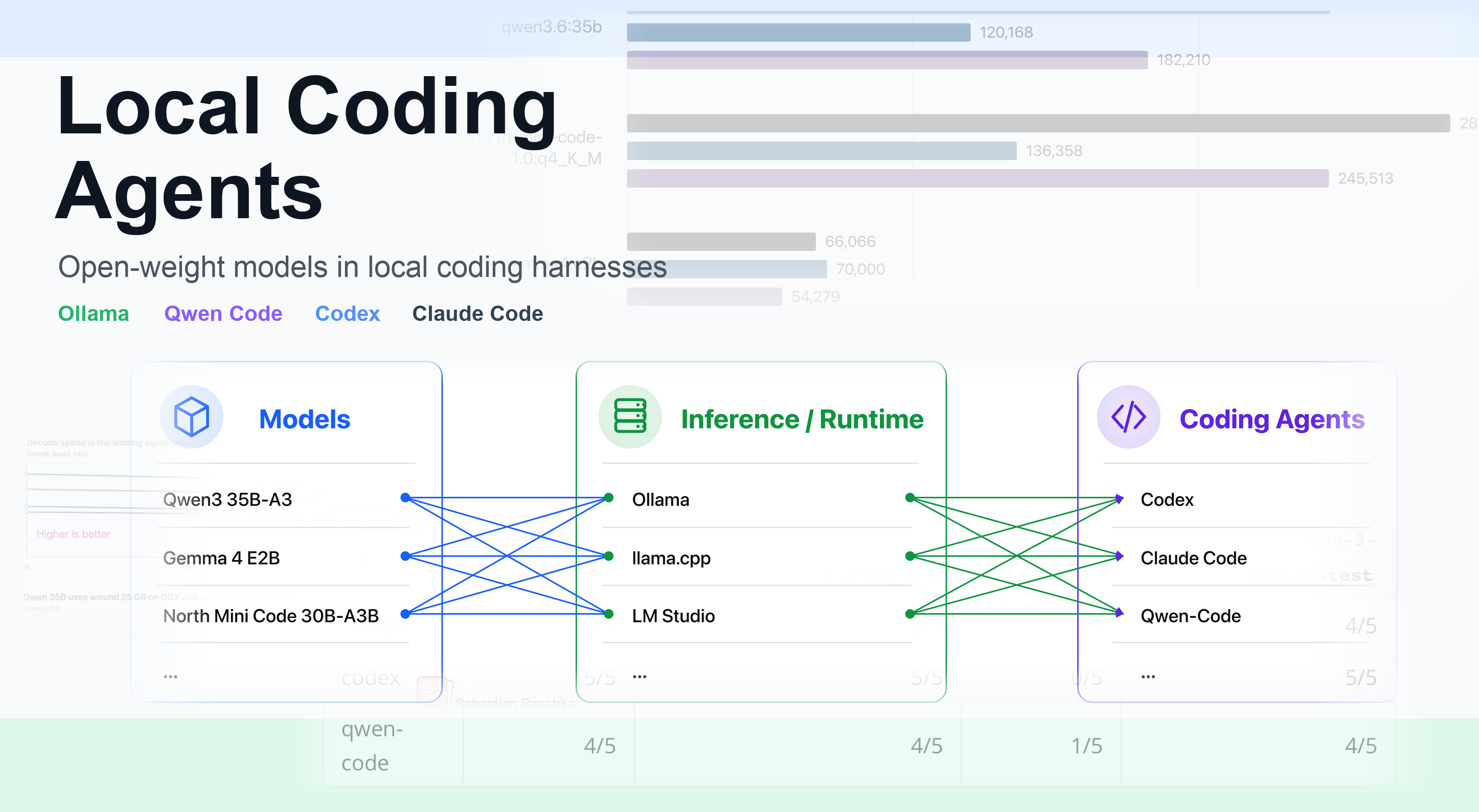

VentureBeat AI· 9 min read· Yesterday
Trunk Tools' stack cut document review from 60 days to 10 by ditching general-purpose models

AWS ML Blog· 21 min read· 3 days ago
Best practices for multi-turn reinforcement learning in Amazon SageMaker AI

MIT News AI· 5 min read· Jun 26, 2026
LLMs help robots understand vague instructions and focus on key details

SiliconANGLE AI· Jun 25, 2026
Exclusive: LucidLink launches MCP server to give AI agents shared access to distributed files

Amazon Science· 5 min read· Jun 10, 2026
Graviton5’s improved design increases speed and energy efficiency — beyond Moore’s law



NVIDIA Blog· 5 min read· 5 days ago
How NVIDIA’s Inference Software Stack Powers the Lowest Token Cost

MIT News AI· 6 min read· Jun 23, 2026
New chip could help tiny robots traverse complex environments

SiliconANGLE AI· Jun 25, 2026
Agentic infrastructure startup Seltz raises $12.5M to help AI agents search the web for answers

Amazon Science· 16 min read· Jun 8, 2026
Bridging intent and execution in agentic systems

Towards Data Science· 2 days ago
Long Context vs. Short Context Model: When Does a Long Context Model Win?

SiliconANGLE AI· Jun 25, 2026
Memory maker SK hynix files for $29B US IPO amid AI demand

VentureBeat AI· 12 min read· 4 days ago
The Control Gap: Enterprise AI organizations have an ownership problem, not a technology problem — and most are governing it by hand

SiliconANGLE AI· Jun 24, 2026
Qualcomm shares jump 14% on Modular acquisition, guidance upgrade

NVIDIA Blog· 4 min read· 6 days ago
Open Models, Closed Environments: Palantir Brings Secure AI to US Agencies With NVIDIA Nemotron

SiliconANGLE AI· Jun 24, 2026
Grammarly parent Superhuman buys AI detector GPTZero

Towards Data Science· 3 days ago
Tokenminning: How to Get More from Your Chatbot for Less
NVIDIA Blog· 4 min read· Jun 24, 2026
NVIDIA and AWS Collaborate to Bring AI to Production at Scale
Towards Data Science· 4 days ago
Persistent Latent Memory for Multi-Hop LLM Agents: How a 6G Handover Paper Closes the Agent Cold-Start
Towards Data Science· 4 days ago
What Can We Do When Memory Becomes the New Bottleneck in Data Engineering?

AWS ML Blog· 12 min read· 5 days ago
Implementing resilience patterns with Amazon Bedrock and LLM gateway
AWS ML Blog· 7 min read· 5 days ago
How Outpost VFX Uses AWS to Accelerate AI Model Training for Visual Effects
AWS ML Blog· 12 min read· 5 days ago
Fine-tune Amazon Nova models for accurate email data extraction
AWS ML Blog· 15 min read· 6 days ago
Pair Nova 2 Lite with Claude for cost-optimized document processing
SiliconANGLE AI· Jun 24, 2026
Upbound open-sources Modelplane to optimize inference clusters


SiliconANGLE AI· Jun 23, 2026
Momentic raises the bar for software testing with agentic quality platform
NVIDIA Blog· 4 min read· Jun 23, 2026
NVIDIA Powers Over 400 of the World’s 500 Fastest Supercomputers
MIT News AI· 6 min read· Jun 10, 2026
Startup’s nuclear-inspired cooling system could make data centers more sustainable
MIT News AI· 5 min read· Jun 9, 2026