Using Local Coding Agents
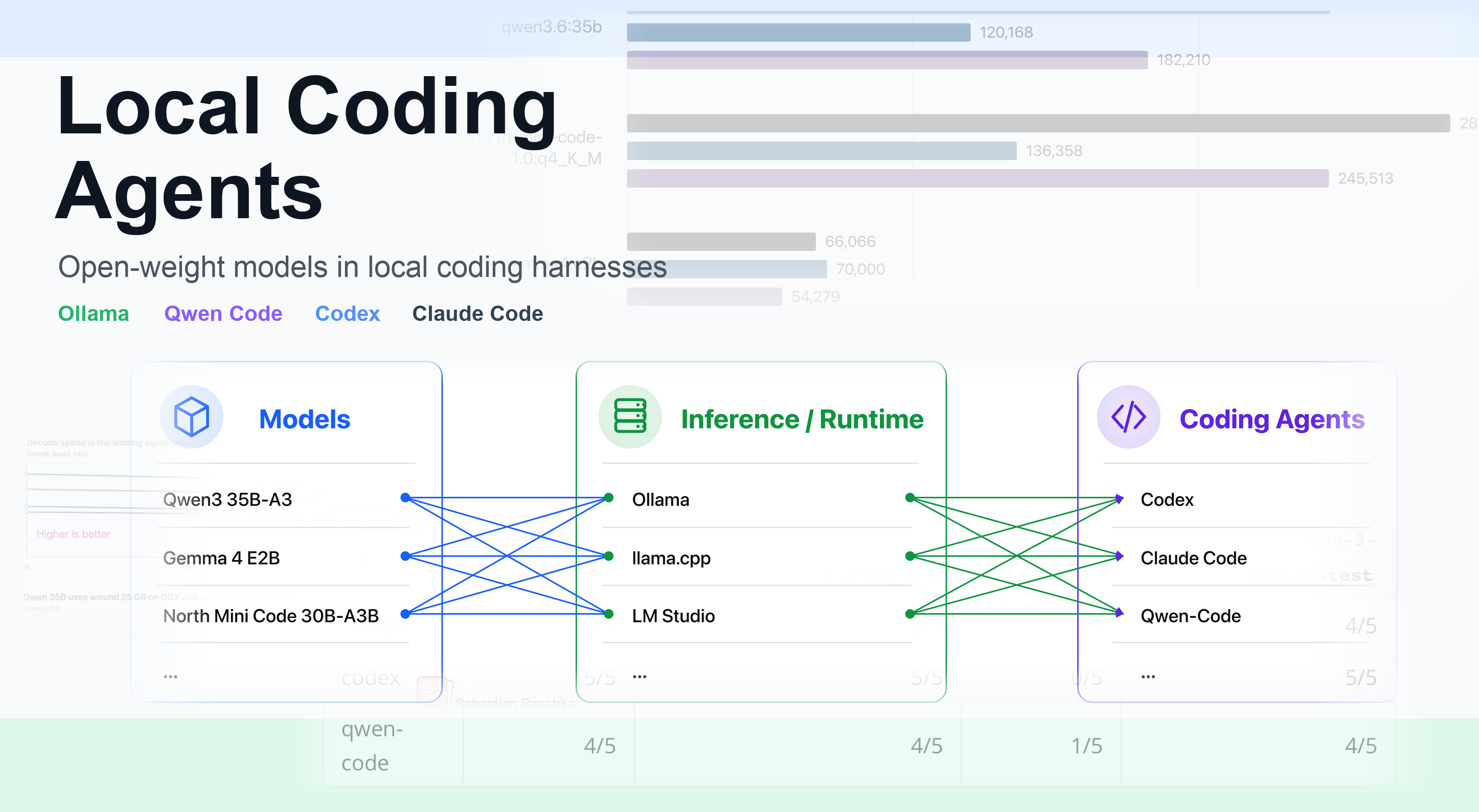
This article provides a tutorial on setting up a production-ready local coding agent using open-source tools and open-weight large language models (LLMs). The local stack consists of a coding agent harness that uses a local model hosted through an inference engine/runtime server, allowing for transparent, inspectable, and cost-effective coding workflows. The author highlights the benefits of local solutions, including predictable costs, reproducibility, and offline use. The practical implication for engineers building AI systems is the ability to create custom, flexible, and cost-effective coding agents that can be tailored to specific needs.
⚡ Key Takeaways
- The local stack uses a locally served LLM together with a local coding harness that can read files, make edits, run commands, and verify changes.
- Open-weight LLMs can be used as an alternative to proprietary services like GPT in Codex or Opus in Claude Code.
- Local solutions offer predictable, fixed costs, and immunity to API price changes.
- Reproducibility is a key benefit of local solutions, as model upgrades can break existing workflows.
- Offline use is possible with local solutions, making them suitable for scenarios with slow or no internet.
For engineers building AI systems, using local coding agents can provide a high degree of control, flexibility, and cost-effectiveness, making it an attractive alternative to proprietary services. By setting up a local stack, engineers can create custom coding agents that meet specific needs and requirements.
✅ Practical Steps
- Set up a local inference engine/runtime server to host the open-weight LLM.
- Choose a popular coding harness like Codex or Claude Code and integrate it with the local LLM.
- Configure the coding harness to read files, make edits, run commands, and verify changes.
Want the full story? Read the original article.
Read on Ahead of AI ↗