HOT
◆The Competitive Moat That AI Can't Replicate◆Only 16 Percent of Americans Think AI Will Have a Positive Impact on Society◆Launch HN: Adam (YC W25) – Open-Source AI CAD◆Pentagon boasts of using AI to write reports mandated by Congress (1.5mil users)◆Sixty percent of US consumers say 'AI' in brand messaging is a turnoff◆The founder's playbook: Building an AI-native startup◆Has AI already killed self-help nonfiction books?◆After AI takes everything◆Show HN: Veterinarian turned founder, AI lawn diagnosis◆My Homelab AI Dev Platform◆The Competitive Moat That AI Can't Replicate◆Only 16 Percent of Americans Think AI Will Have a Positive Impact on Society◆Launch HN: Adam (YC W25) – Open-Source AI CAD◆Pentagon boasts of using AI to write reports mandated by Congress (1.5mil users)◆Sixty percent of US consumers say 'AI' in brand messaging is a turnoff◆The founder's playbook: Building an AI-native startup◆Has AI already killed self-help nonfiction books?◆After AI takes everything◆Show HN: Veterinarian turned founder, AI lawn diagnosis◆My Homelab AI Dev Platform
Daily AI Signal for Engineers
LLMs · RAG · Agents · Production Tools
Hand-picked news from 50+ sources + original engineering deep dives.
No hype, just signal.
Updated dailyOriginal articlesFree forever
Weekly AI digest every Sunday · No spam
From the Blog
In-depth takes on AI engineering
Today's AI Feed
63 articles today




· 6 min read· Yesterday
Databricks and NVIDIA: Building for the Agentic Era

· 6 min read· Yesterday
In game theory, generalists sometimes win out over specialists




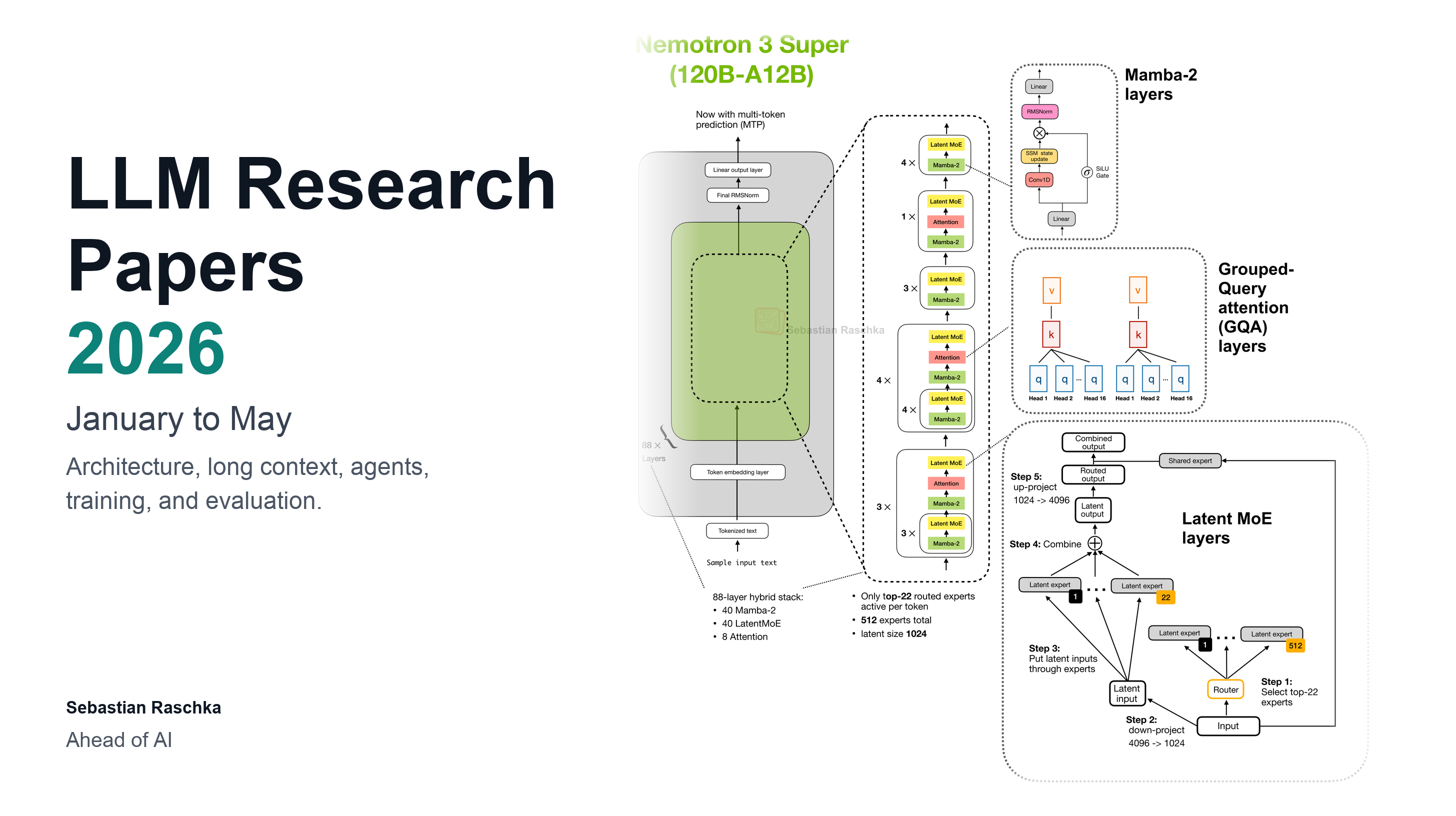

· 8 min read· May 24, 2026
The Pulse: Forward deployed engineering heats up again








· 6 min read· May 14, 2026
