LLM
Large Language Models (LLMs) are the foundation of modern AI applications. Coverage includes model releases, fine-tuning techniques, inference optimization, and production deployment patterns.
41 articles
41 articles


MIT News AI· 5 min read· 2 days ago
LLMs help robots understand vague instructions and focus on key details

CMU ML Blog· 8 min read· Jun 19, 2026
Healthcare Benchmarks Are Only as Good as Their Assumptions

Spotify Labs· May 18, 2026
Better Experiments with LLM Evals — A funnel, not a fork

VentureBeat AI· 7 min read· Yesterday
Claude Code turned every engineer into three. Now companies need more product thinkers

Towards Data Science· Today
I Pitted XGBoost Against Logistic Regression on 358 Matches. The Boring Model Won.
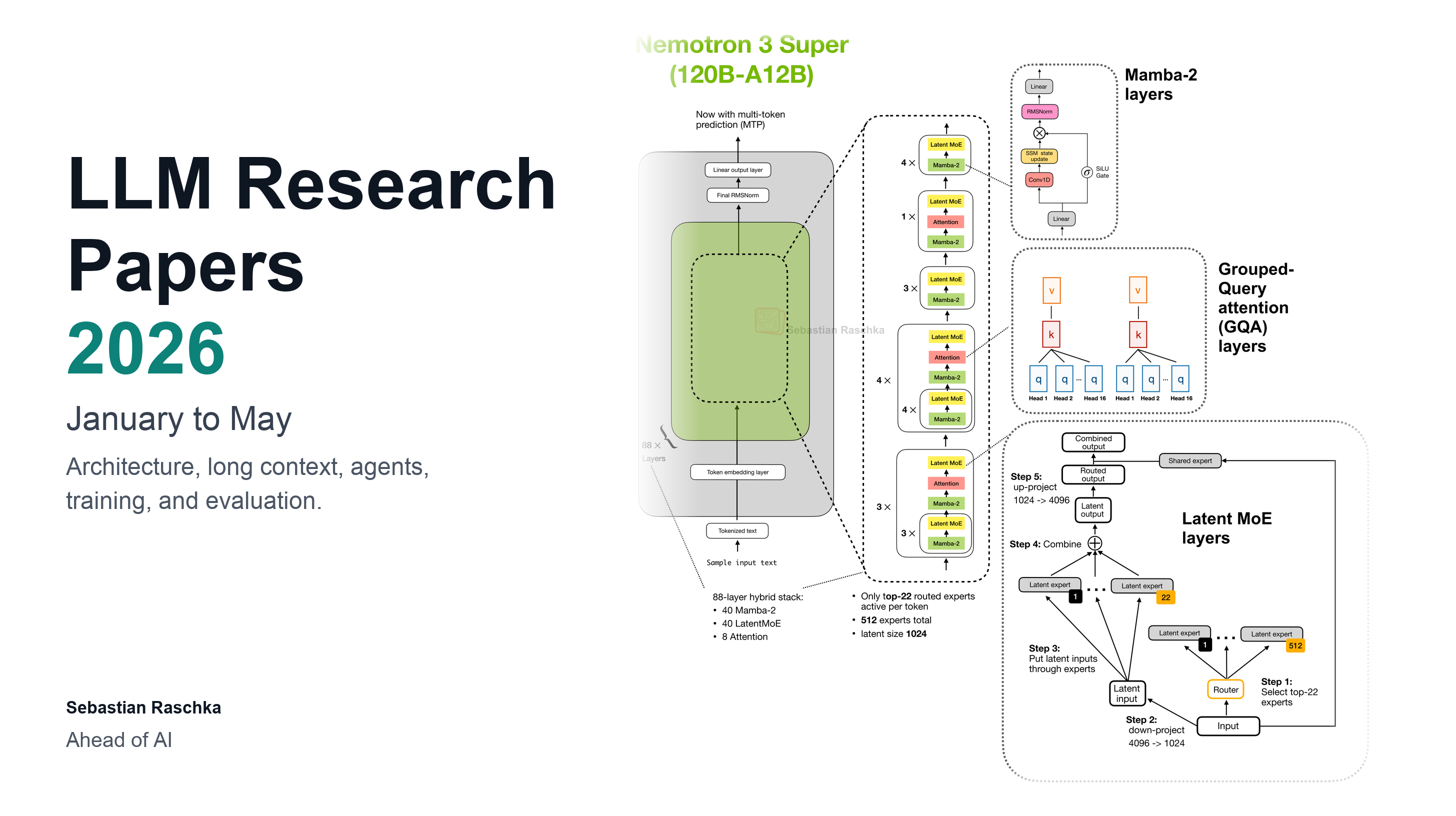
Ahead of AI· 6 min read· Jun 6, 2026
LLM Research Papers: The 2026 List (January to May)
AWS ML Blog· 5 min read· 2 days ago
How Cara pioneers domain-specific AI for enterprise insurance brokerages with AWS


Machine Learning Mastery· 5 days ago
Clustering Unstructured Text with LLM Embeddings and HDBSCAN

NVIDIA Blog· 4 min read· 5 days ago
How Businesses Are Building Specialized AI They Can Trust

VentureBeat AI· 6 min read· 2 days ago
New agentic memory framework uses 118K tokens per query. LangMem burns through 3.26M.

Ahead of AI· 27 min read· May 16, 2026
Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention



Machine Learning Mastery· Jun 16, 2026
Building an End-to-End Sentiment Analysis Pipeline with Scikit-LLM

Amazon Science· 16 min read· Jun 8, 2026
Bridging intent and execution in agentic systems

VentureBeat AI· 11 min read· 2 days ago
OpenAI unveils GPT-5.6 Sol, Terra and Luna models — but only accessible to limited preview partners for now, per US Gov


MIT News AI· 6 min read· Jun 17, 2026
In game theory, generalists sometimes win out over specialists

VentureBeat AI· 6 min read· 2 days ago
Liquid AI's smallest model yet LFM2.5-230M beats models 4X its size at data extraction, can run 'anywhere'


Machine Learning Mastery· Jun 11, 2026
Multi-Label Text Classification with Scikit-LLM

Amazon Science· 5 min read· May 26, 2026
Diverse reasoning traces teach LLMs to make better decisions

Amazon Science· 5 min read· May 15, 2026
Making LLMs faster without sacrificing accuracy

SiliconANGLE AI· 4 days ago
OpenAI, Broadcom debut custom Jalapeño chip for AI inference
Towards Data Science· 3 days ago
The Hot Path Belongs to GBDTs, Agents Own the Cold Path: A Payment-Fraud Benchmark
Towards Data Science· 3 days ago
Beyond the Straight Line: Choosing Between OLS, Interaction Terms, and Tweedie Regression
Towards Data Science· 3 days ago
3 Agents. 3 LLMs. 1 Aging GPU: Engineering Parallel Inference on Bare Metal

Towards Data Science· 3 days ago
An LLM as arbiter in RAG retrieval: picking the right candidate with reasons

AWS ML Blog· 11 min read· 4 days ago
How Loka Built a Natural, Low-Latency Voice Agent with Amazon Nova 2 Sonic

SiliconANGLE AI· 4 days ago
Anthropic debuts Claude Tag, a more capable AI teammate that lives within Slack
AWS ML Blog· 15 min read· 5 days ago
Build a protein research copilot with Amazon Bedrock AgentCore

SiliconANGLE AI· 5 days ago
Momentic raises the bar for software testing with agentic quality platform
AWS ML Blog· 25 min read· 6 days ago
Embed the world: Multimodal AI for searchable aerial imagery at scale
AWS ML Blog· 12 min read· 6 days ago
Running ComfyUI workflows on Amazon SageMaker AI processing jobs
AWS ML Blog· 14 min read· Jun 18, 2026
Monitor and debug generative AI inference with SageMaker detailed metrics and Insights dashboard on CloudWatch

NVIDIA Blog· 5 min read· Jun 18, 2026
At Cannes Lions, NVIDIA Partners Reshape Advertising and Marketing With AI
MIT News AI· 5 min read· Jun 9, 2026