Context vs. Memory Engineering in Agentic AI Systems
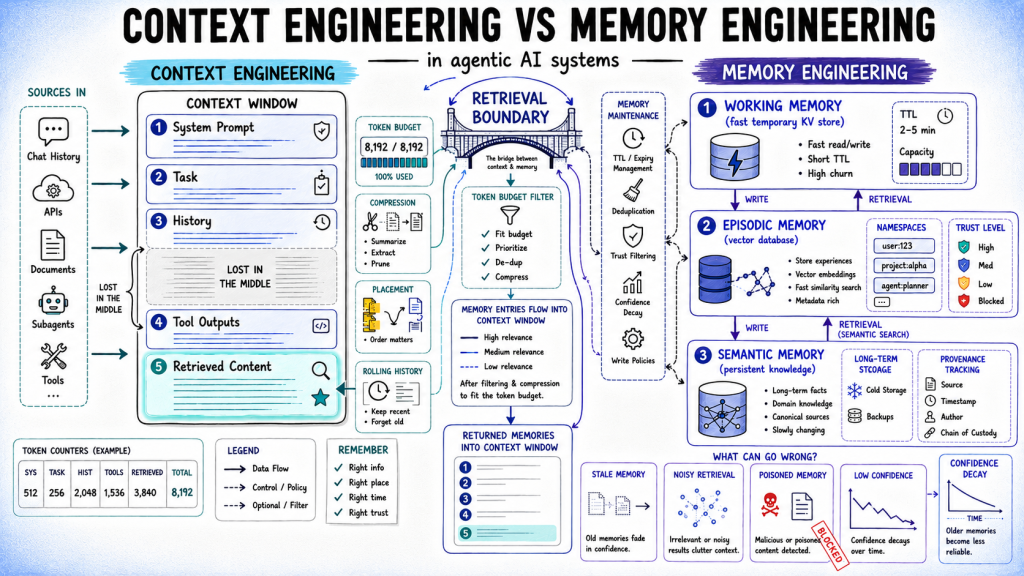
The Context vs. Memory Engineering in Agentic AI Systems discussion highlights the importance of compression timing in Agentic AI Systems. Specifically, it suggests that Compression on Arrival Tool outputs should be compressed after a call returns, rather than after the window fills. This approach can potentially improve system efficiency. The practical implication for engineers building AI systems is to consider the timing of compression in their design.
⚡ Key Takeaways
- Compression on Arrival Tool outputs should be compressed after a call returns.
- The system's efficiency can be improved by compressing outputs after a call returns, rather than after the window fills.
- Real tradeoff — performance, cost, latency, or compatibility is not explicitly mentioned.
- How to actually use or integrate it — the Compression on Arrival Tool is mentioned, but its API or config is not specified.
- Limitation, caveat, or prerequisite — not mentioned.
🔧 Tools & Libraries
The correct timing of compression can significantly impact the performance and efficiency of Agentic AI Systems, making it a crucial consideration for engineers designing these systems. By compressing outputs after a call returns, engineers can potentially reduce latency and improve overall system responsiveness.
✅ Practical Steps
- Compress Compression on Arrival Tool outputs after a call returns, rather than after the window fills.
- Apply the concepts from this article to your own system design, considering the timing of compression in your Agentic AI System.
Want the full story? Read the original article.
Read on Machine Learning Mastery ↗